
My research focuses on drawing theoretical insights from learning science and exemplary techniques from the fields of human-computer interaction, learning analytics and explainable AI to design, implement, validate and deliver technological solutions that contribute to the delivery of learner-centred, data-driven learning at scale. My past research and publications have addressed a number of diverse topics such as learning graphical models, statistical-relational learning, social network analysis, cybersecurity and game theory.
RiPPLE: A Learnersourced Adaptive Educational System
Inprogress UQ Started in 2017At a time of heightened interest in online learning and AI, there is a growing consensus that adaptive educational systems (AESs) can have a transformational impact on the educational landscape. AESs dynamically adjust the level or type of instruction based on individual student competencies and have demonstrated to have the ability to provide high-quality personalised learning opportunities for diverse learners at scale. However, the adoption and impact of AESs has been limited by the need to access large repositories of learning resources commonly created by domain experts. They are expensive to develop and challenging to scale. To address this, My team and I have developed a learnersourced adaptive educational platform, RiPPLE. Featured as an exemplar in the 2019 EDUCAUSE Horizon Report and Review, RiPPLE employs learner-centred and pedagogically supported approaches to engage students in authentic learning experiences. It harnesses the creativity and evaluation power of students as experts-in-training to develop a repository of high-quality learning resources. The RiPPLE platform uses AI algorithms, to calculate a student's level of knowledge on each course topic based on their engagement with resources and recommends personalised learning activities to each student based on their mastery leve. To help students regulate their learning, RiPPLE uses transparent and explainable AI models to allow students to understand how their mastery is computed and why particular resources have been recommended to them. RiPPLE's AI spot-checking algorithm enables academics to effectively facilitate students' content creation and evaluation contributions with minimal oversight. This algorithm identifies resources that would benefit the most from an expert judgement and presents them to academics.
For more inforamtion please visit ripplelearning.org/.

Intelligent Learning Analytics Dashboards
Inprogress UQ Started in 2019Learning analytics dashboards commonly visualise data about students with the aim of assisting students and educators in understanding and making informed decisions about the learning process. To assist with making sense of complex and multi-dimensional data, many learning analytics systems and dashboards have relied significantly on AI algorithms based on predictive analytics. While predictive models have been successful in many domains, there is an increasing realisation of the inadequacies of using predictive models in decision-making tasks that affect individuals without human oversight. In this project, we employ a suite of state-of-the-art algorithms, from online analytics processing, data mining and process mining domains, to present an alternative human-in-the-loop AI method to enable educators to identify, explore and use appropriate interventions for subpopulations of students with the highest deviation in performance or learning process compared to the rest of the class. The project demonstrates an example of how human-in-the-loop AI methods can be employed in the development of successful learning analytics dashboards.

Accurate and Explainable Consensus Approaches
Inprogress UQ Started in 2019In decision-making tasks, due to the potential that the decision made by an individual might be incorrect, many systems employ a redundancy-based strategy and assign the same tasks to multiple individuals. The problem of optimal integration of the crowdsourced decisions in the absence of a ground truth towards making an accurate final decision has been studied extensively within the crowdsourcing community \cite{zheng2017truth}. Many of the state-of-the-art consensus approaches rely on machine learning algorithms to simultaneously infer the true outcome and workers' reliability. While using machine learning algorithms have significantly improved the accuracy of the models compared to averaging aggregation functions, these methods often lack understandability and transparency (in terms of how individuals were rated and how a final decision was made). The use of black-box outcomes seems to be particularly inadequate for educational settings where educators strive to provide extensive feedback to enable learners to develop their own vision, reasoning, and appreciation for inquiry and investigation and fairness. Much of the existing work on the need for open and explainable AI models in education has been conducted in the field of open learner models. This project focuses on development and evaluation of accurate and explainable consensus approaches that can be used in education.
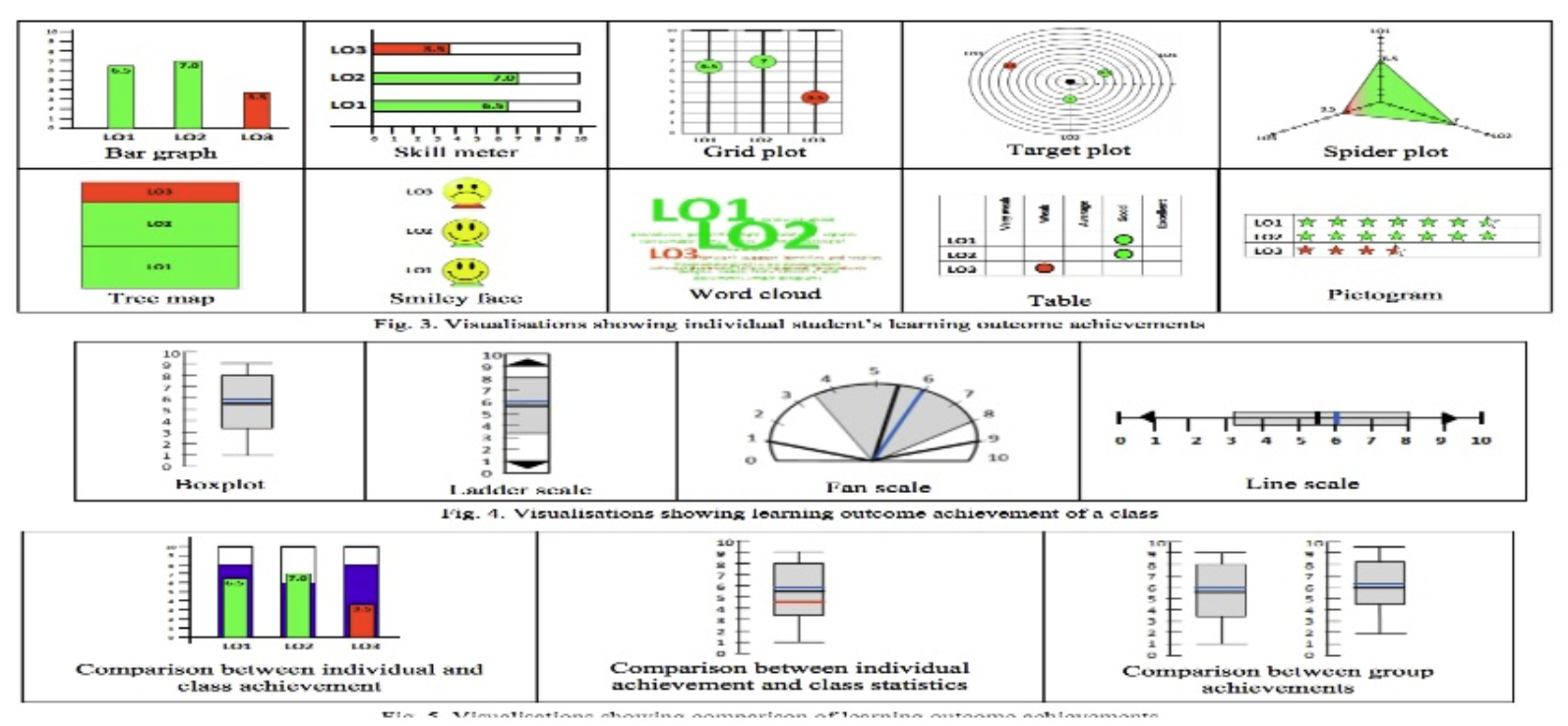
Open Learner Models in Adaptive and Learnersourced Educational Systems
Inprogress UQ Started in 2019Development of strategies and approaches that assist students in better understanding of how their learning is captured and approximated in educational systems has been studied in a field–commonly referred to Open Learner Models (OLMs). Simply put, OLMs are learner models that are externalised and made accessible to students or other stakeholders such as instructors. They are often opened through visualisations, as an important means of supporting learning. The aim of this study is to develop OLMs in adaptive and learnersourced educational systems that not only accurately represent students' mastery level but also promotes self-regulation and positive behaviour that contributes to learning in students.
Past Projects

Reciprocal Peer Recommendation for Learning Purposes
Inprogress UQ Started in 2017
Analysing Students' Exam Logs Generated by an Electronic Assessment Platform
Inprogress UQ Started in 2018The overall goal of the proposed research is to understand students’ behaviours while sitting electronic exams. More specifically, the study seeks to identify the different patterns associated with those behaviours and investigate whether a correlation exists between these patterns and the students’ e-exam results. In order to achieve this goal, we will first collect students' e-exam data from logs generated by the ExamSoft electronic assessment platform for a course held at e University of Queensland. We will then use data mining methods and machine learning techniques for the analysis.
The study’s findings will help educators determine whether certain exam-taking behaviours are associated with students' performance on examinations. They can then use this information to provide valuable feedback to students, such as suggesting effective strategies to enhance student performance on upcoming exams.
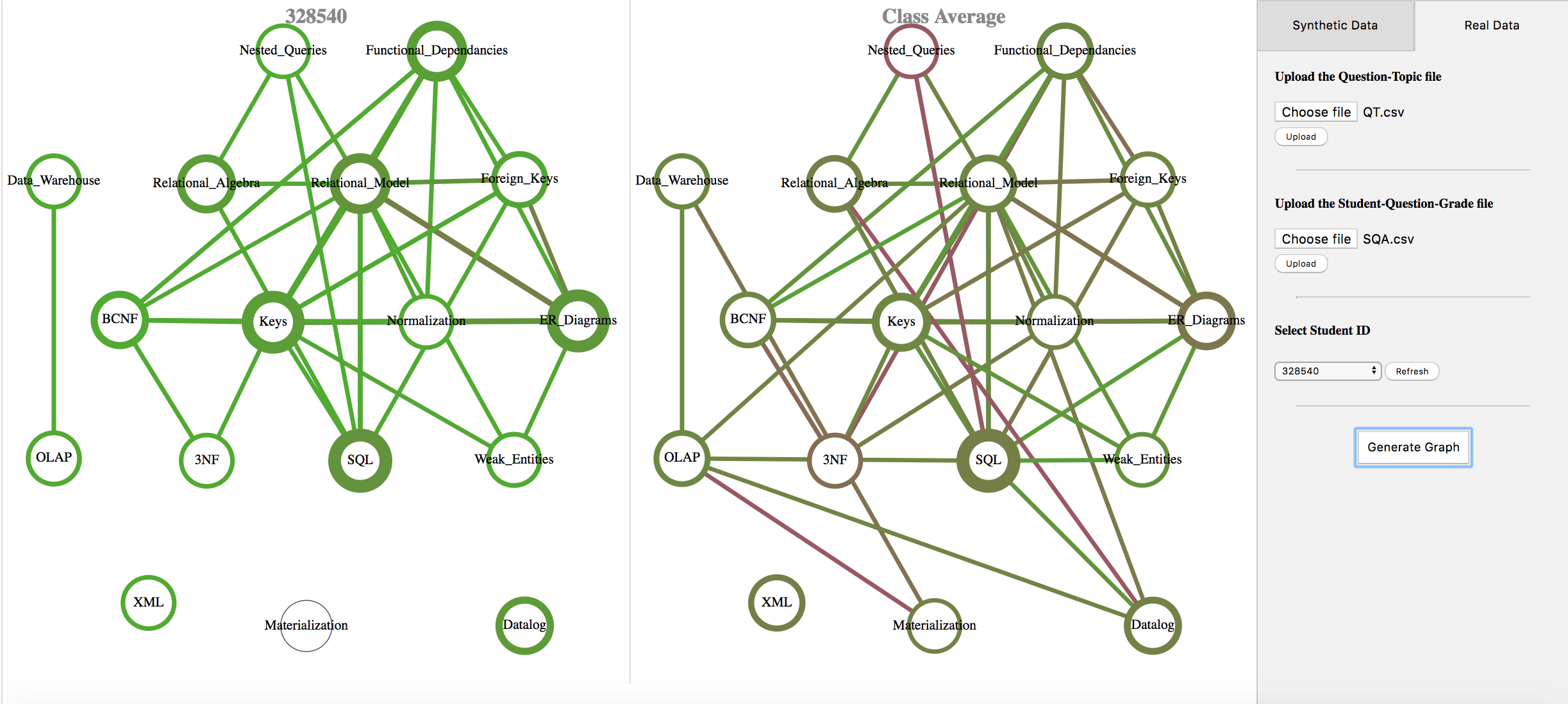
Topic Dependency Models
Inprogress UQ Started in 2016Educational environments continue to rapidly evolve to address the needs of diverse, growing student populations, while embracing advances in pedagogy and technology. In this changing landscape ensuring the consistency among the assessments for different offerings of a course (within or across terms), providing meaningful feedback about students’ achievements, and tracking students’ progression over time are all challenging tasks, particularly at scale. Here, a collection of visual Topic Dependency Models (TDMs) is proposed to help address these challenges. It uses statistical models to determine and visualise students’ achievements on one or more topics and their dependencies at a course level reference TDM (e.g., CS 100) as well as assessment data at the classroom level (e.g., students in CS 100 Term 1 2016 Section 001) both at one point in time (static) and over time (dynamic). The collection of TDMs share a common two-weighted graph foundation. Exemplar algorithms are presented for the creation of the course reference and selected class (static and dynamic) TDMs; the algorithms are illustrated using a common symbolic example. Studies on the application of the TDM collection on data sets from two university courses are presented; these case studies utilise the open-source, proof of concept tool under development.
A prototype of the system and more information about the platform are available here.
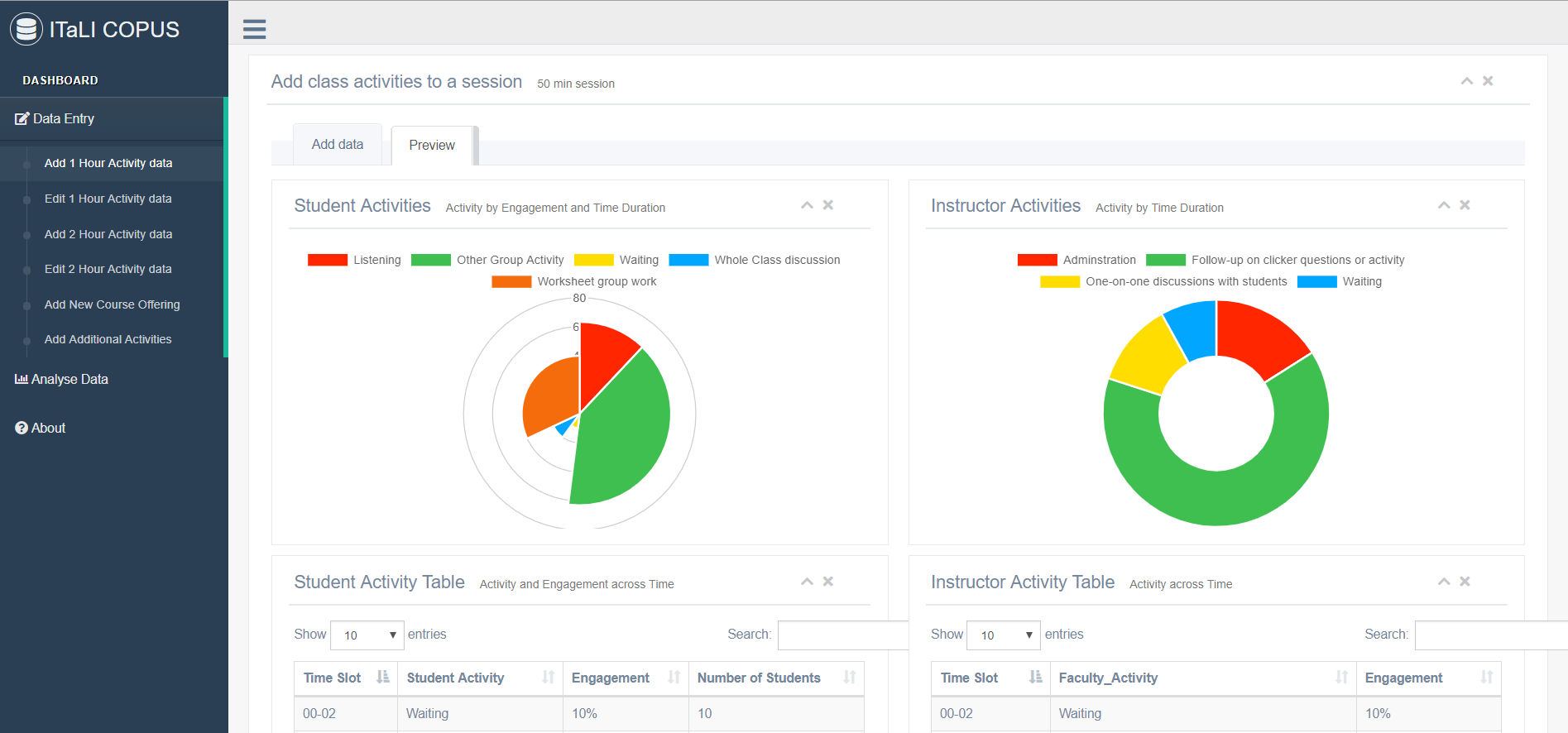
The Classroom Observation Protocol Project
Inprogress UQ Started in 2017The aim of project is to provide a scalable way to implement COPUS protocols for quantifying aspects of teaching. The platform created will allow instructors to judge accurately how much time they are spending in active learning versus a more traditional lecture. This will allow instructors to make more informed decision about how they might modify their future class work. In short term, the project will trigger more active learning in lectures in UQ and in the long term allow other institutions to scalably implement COPUS research tool while meeting data privacy concerns.
The platform is avaiable for use at UQ here

Learning and Mining Education Data
completed UBC 2016The first-year engineering students at UBC use Blackboard to access the preparatory material for a course covering an introduction to programming. The data features of most interest to this project are the video screencasts, practice worksheets, pre-laboratory assignments, practice midterm exams and solutions, and solutions to the students’ actual previously written midterms. The main goals of this research project were to use machine learning and data mining algorithms to:
uncover relationships and patterns in the dataset that will help evolve the course (and potentially other courses) or provide useful recommendations to future students taking the course. For example, an interesting pattern is that students that watch screencasts at midday as opposed to late at night perform better on exam questions, and a beneficial recommendation is reporting that there is a limitation to the effectiveness of multiple viewings of a screencast (e.g., watching a screencast for a fifth time would probably not be a good use of a student’s time).
-
evaluate how students’ engagement and commitment to studying outside lectures, throughout the semester, is correlated with their performance on quizzes and exams, and whether it is possible to use linear regression or probabilistic graphical models to obtain a model that can accurately predict the exam grade of students based on their behavior throughout the semester

Peer Learning and Assessment Outside the Classroom
completed UBC 2016Use of clickers is a great way to foster effective engagement and peer learning among students; however, creating a meaningful and engaging environment for peer learning during lecture is time consuming, so unfortunately most of the time, the use of clickers needs to be shortened to provide time for the course content to be covered. As such, there is much interest and desire in exploring methods that allow students to have a similar peer learning experience outside the classroom.
PeerWise is a free web-based system in which students create multiple-choice questions, and answer, rate, and discuss questions created by their peers. It empowers students to generate their own multiple-choice questions and allows them to share them with one another.One of the shortcomings of PeerWise is that the created content cannot be exported and be used outside of the PeerWise platform. We have developed an open source framework that allows the content to be exported into a locally stored database and to be used without relying on PeerWise. The framework is easy to deploy and requires no intervention from the IT department. A prototype of the framework is available at https://github.com/hkhosrav/peerwise-flashcard

User Modeling on Smart Devices
completed FusionPipe 2014-2015Decisions on how to proceed when a device with confidential corporate information has been compromised are a function of the sensitivity of the stored data as well as policies of the host company. A traditional method of dealing with compromised devices aims to wipe the device remotely; however, such methods are particularly impractical when the signal is prevented. The two main components of this research project were the following:
Learning phase: We used machine learning techniques in data acquisition to extract features pertain- ing to a user’s interaction with a device to differentiate users’ patterns of interaction. Such data were utilized to build a probabilistic graphical model, which provides the basis for intelligent detection of unauthorized usage of the device. Sources such as meeting schedules, geographical data from GPS, available WiFis, internet traffic, patterns of how an application is used, and communication of the device with other devices such as smartwatches or laptops may be used for learning the model.
-
Compromise detection through inference: The model periodically updates its assessment from the state of the device. Once the model reaches a certain likelihood that the device is compromised, it triggers adaptive intervention, which allows the device to intelligently make decisions on its own. This includes remote/self termination of corporate information while fooling the attacker by revealing some false attractive information (honeypot methods). In case of availability of a signal the device may first transfer the prioritized information to a secure data store through cloud services, and then inform a reliable source, through email, of its current state and location.
We successfully designed a health agent, as a framework, that monitors and analyzes the behavior of a smart device and makes decisions on the health status of that device.

Behavioral Authentication on Smart Mobile Devices Using Probabilistic Graphical Models
completed UBC 2015-2016This work is an extension over the “User Modeling on Smart Devices” project, in which we developed an algorithm that uses behavioral data such as touchscreen gestures, body movement styles, and holding patterns for authentication on mobile devices. We demonstrate that considering universality, permanence, performance, uniqueness, collectability, and circumvention behavioral biometrics, like physical biometrics, are ideal candidates for authentication. In addition, behavioral biometrics, unlike physical ones, have the advantage of supporting continuous authentication, being non-obtrusive, and cost effective. We developed a framework that uses probabilistic graphical models to learn the behavior of a user during an enrollment phase and is able to later classify whether the person interacting with the device is the true user or not. Experimental results from three datasets demonstrate that behavioral data from mobile devices are distinctive enough to serve as a biometric in verifying users.

Decoupling User Authentication and Data Encryption on Mobile Devices
completed FusionPipe 2014-2015Various forms of confidential data are stored on smart devices for the benefit of being accessible “on-the- go”, which creates the necessity for protecting “data-at-rest” on these devices. Data encryption with a randomly generated encryption key can be applied; however, since the device has to be able to work in off-line scenarios, the encryption key has to be stored on the device, along with data. In order to overcome this limitation, all major mobile platforms encrypt the encryption key with a so called key encryption key. The key encryption key is derived from a secret that is used to authenticate smartphone users (e.g., a PIN-code, or password). Unfortunately, PIN-codes are weak and are prone to brute-force attacks. In this work we presented and evaluated the KeyVault system that breaks the dependency between the security of data encryption and the secrecy of human memorable authentication secret. The main objective of the KeyVault system is to improve security of the data that are physically stored on the mobile devices. In order to achieve this we developed a framework to store the encryption keys on a separate device, and use wireless technologies to make them available when they are needed. This research led to the filing and approval of a full non-provisional patent titled ”Method and system for decoupling user authentication and data encryption on mobile devices”.
Conspiracy of Multiple Devices to form the Appearance of a Single Authenticated End Point
completed UBC 2015-2016TBA

Using Cloud Computing for Disaster Recovery
completed FusionPipe 2012-2013Disaster recovery is an essential part of many businesses. A typical disaster recovery service works by replicating the data and the applications among multiple data centers. There are numerous technical challenges in traditional disaster recovery that make it expensive, slow, and complex for small or mid-sized enterprises. Traditional disaster recovery often entails very high cost, or provides very weak guarantees about the amount of data lost or time required to restart the operation after a failure. These challenges include the following: (1) successful recovery requires identical hardware configuration at the primary site and recovery sites, which often leads to expensive new server purchases, (2) complex system imaging tools and restore processes require special skills and resources which are costly and time consuming to integrate, and (3) snapshot based approaches limit the ability to retrieve individual files (or incremental changes) in the VM images.
The primary goal of the project was to develop disaster recovery for virtual machines as a cloud service. The idea is to use cloud computing instead of physical recovery sites for replication of applications and data. Our implementation allows two layers of recovery. The most delicate data and applications, tier 1 information, are stored on a hot standby recovery system, which is expected to start running within minutes after the disaster. Our implementation used a private cloud, operating on the open source OpenStack system, as the hot standby. Less delicate data and applications, tier 2 information, are stored on a warm standby recovery system. A warm standby recovery is expected to launch within a few hours of the disaster. We used Amazon Web Services as the warm standby.
Optimization of Cloud Usage on Amazon AWS
completed FusionPipe 2012-2013The main goal of this project was to assist cloud consumers in optimizing cloud resource utilization. In particular, optimizing the costs incurred by provisioning infrastructure from the public cloud and the cost of software licenses, both on demand and perpetual, was targeted as the main aim of this project. This aim could be achieved by empowering the users of the cloud to gain better insight into the current cloud resources being provisioned and providing them with alternative solutions which could carry out the needs of the users with the same or even higher efficiency while imposing less cost in their usage bills. We successfully implemented an engine that optimizes the infrastructure and license utilization of the cloud users based on monitoring the cloud utilization on a real-time basis and using the knowledge base that we implemented.
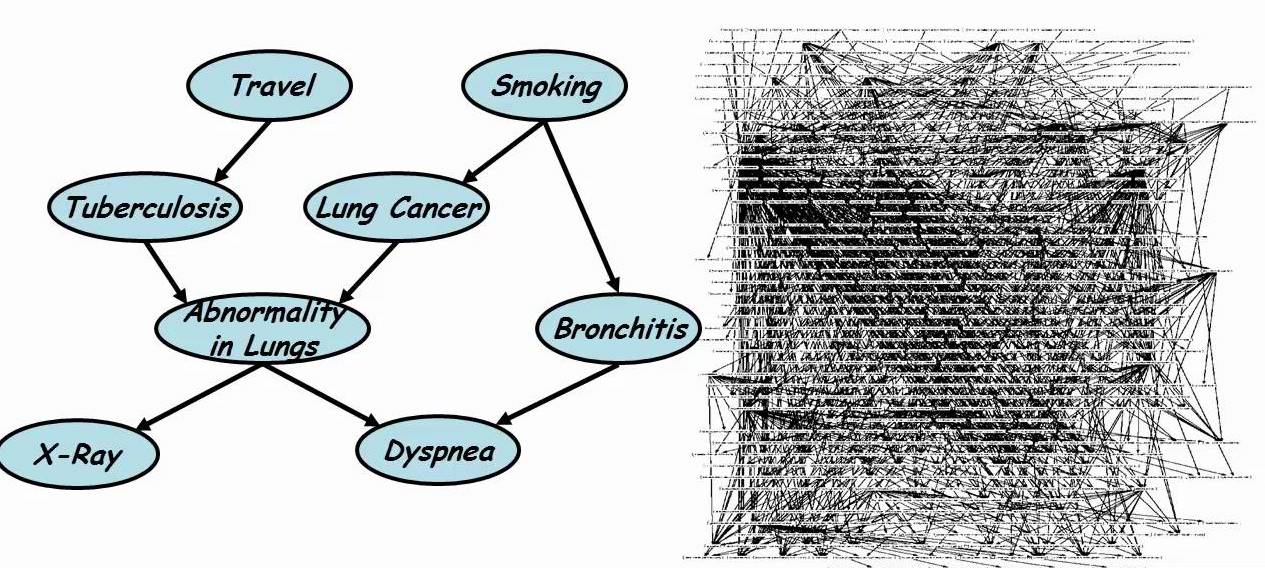
Modelling Relational Statistics With Bayes Nets
completed SFU 2017-2012My PhD dissertation was focused on graphical models in machine learning; in particular, on combining the scalability and efficiency of learning directed relational models, and the inference power and theoretical foundations of undirected relational models. The five years I spent on obtaining my PhD have been invaluable to my life and career, allowing me to acquire a solid foundation in machine learning, developing an appreciation for inquiry, innovation and research-based activities, and gaining experience in performing and reporting scientific research. Four of my significant contributions to research and development during my PhD was published in the Machine Learning Journal, which is one of the most prestigious journals in the field of machine learning. Executable, scripts, datasets, examples can be accessed at http://www.cs.sfu.ca/~oschulte/BayesBase/BayesBase.html
The global rise of education through MOOCs and larger student intakes by universities has led to less direct contact time with teaching staff for each student. One potential way of addressing this contact deficit is to invite learners to engage in peer learning and peer mentoring; however, learners are often hesitant to reach out to their peers or/and are unable to discover suitable peer connections that can best help them learn or enhance their learning experience. Two different research subfields with ties to recommender systems provide partial solutions to this problem. Reciprocal recommender systems provide sophisticated filtering techniques that enable users to connect with one another. To date, however, the main focus of reciprocal recommender systems has been on providing recommendation in online dating sites. Recommender systems for technology enhanced learning have employed and tailored exemplary recommenders towards use in education; however, their main focus has been on recommending learning content and not users. In this project, we expand on the work that has been done in these two subfields to first describe how reciprocal recommendation for learning purposes have fundamental differences with those used for online dating. We then extend an online, educational platform that we have previously developed to provide reciprocal peer recommendation. The feasibility and scalability of the extended platform, which will be trialled in four large on-campus courses at UQ in 2018, are both evaluated using synthetic data sets. Our results indicate that the system can help learners connect with peers based on their knowledge gaps and reciprocal preferences.